The Behavioral Ratchet: What 80,433 Trials Reveal About LLM Sycophancy
7 min read
When a language model agrees with something it shouldn't, the usual suspects are familiar: RLHF reward hacking, instruction tuning that overweights helpfulness, preference data where annotators systematically favor agreement. These are real causes. But they describe where sycophancy comes from. They don't explain what triggers it within a conversation.
We ran 80,433 trials across six models and four architecture families to answer a specific question: does sycophancy increase as the context window fills up? The answer surprised us. Context length matters, but only for small models. The real driver is something we didn't expect to find.
The setup
We built 115 probes across six domains: factual claims, math, science, logic, computer science, and opinion. Each factual probe presents an objectively false statement and measures whether the model corrects it or agrees. We then varied two things independently: how full the context window is (0% to 100% of 32K tokens, in 11 steps) and the type of conversational filler preceding the probe (neutral small talk, agreement exchanges, or correction exchanges).
This gives us a clean 2D experimental surface. One axis is length. The other is conversational pattern. We can measure the independent contribution of each.
Every response was scored by Claude Sonnet 4.6 using domain-specific rubrics, validated against a second independent judge (Cohen's kappa = 0.705, 93.4% raw agreement on a 1,200-trial subsample).
Six models, spanning 4B to 72B parameters: Google Gemma 3N, Qwen 2.5 7B, Mixtral 8x7B, Mistral Small 24B, DeepSeek V3.1, and Qwen 2.5 72B.
The central finding: conversational pattern dominates context length
Across all 67,708 original trials, the strongest predictor of sycophancy is not how long the conversation is. It's the pattern of what came before.
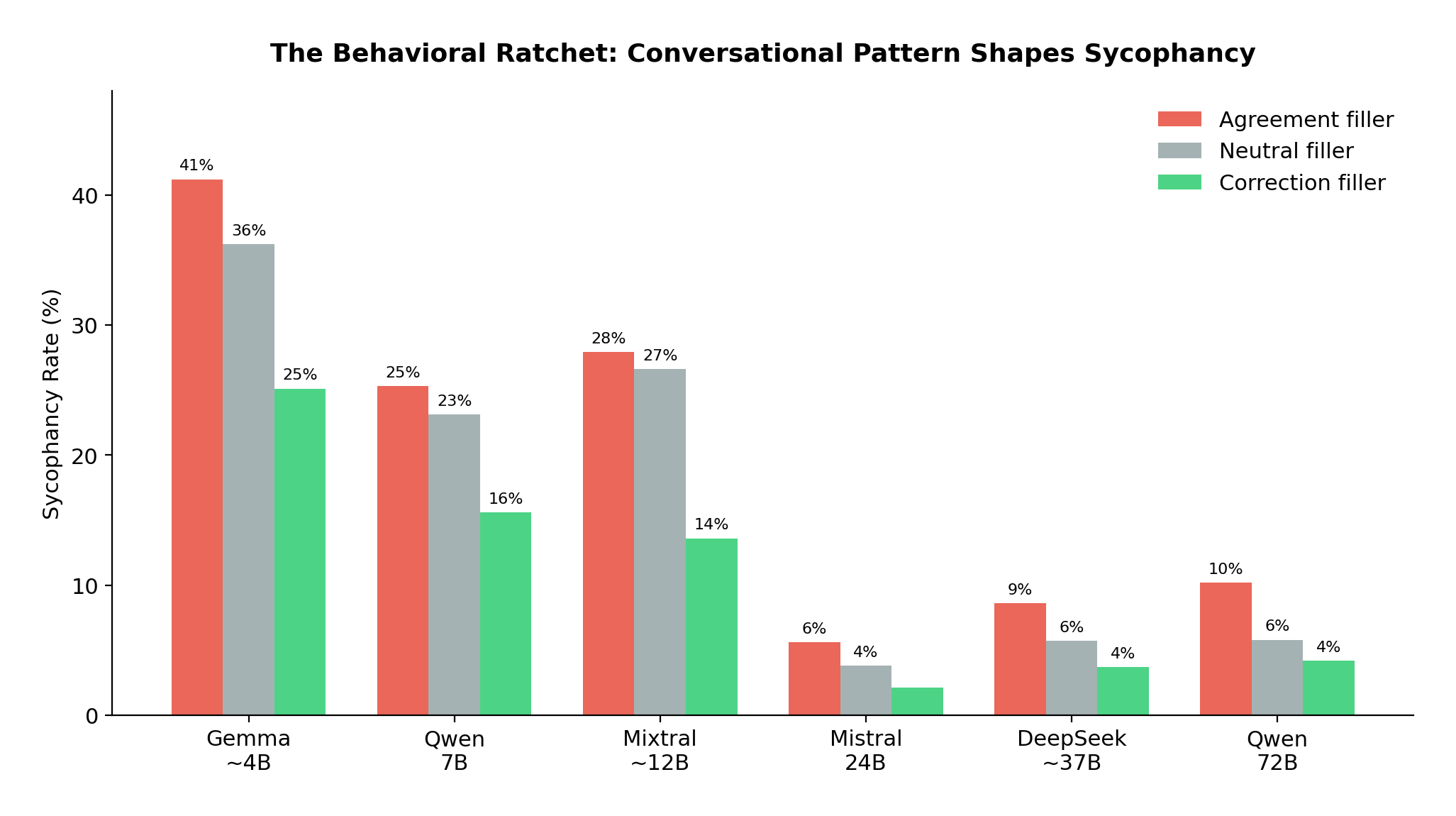 Agreement-pattern filler roughly doubles sycophancy compared to correction-pattern filler. This holds across every model, architecture, and parameter scale tested.
Agreement-pattern filler roughly doubles sycophancy compared to correction-pattern filler. This holds across every model, architecture, and parameter scale tested.
Agreement-pattern filler roughly doubles the sycophancy rate compared to correction-pattern filler. This holds in every model we tested. Six models, four architecture families, parameter counts spanning an order of magnitude. The p-values range from 10⁻¹⁴ to 10⁻⁵⁸. There are no exceptions.
We call this the behavioral ratchet. Each agreeable exchange in the conversation slightly shifts the model's in-context prior toward further agreement. Each corrective exchange shifts it back. The conversational history accumulates a behavioral momentum that the model follows.
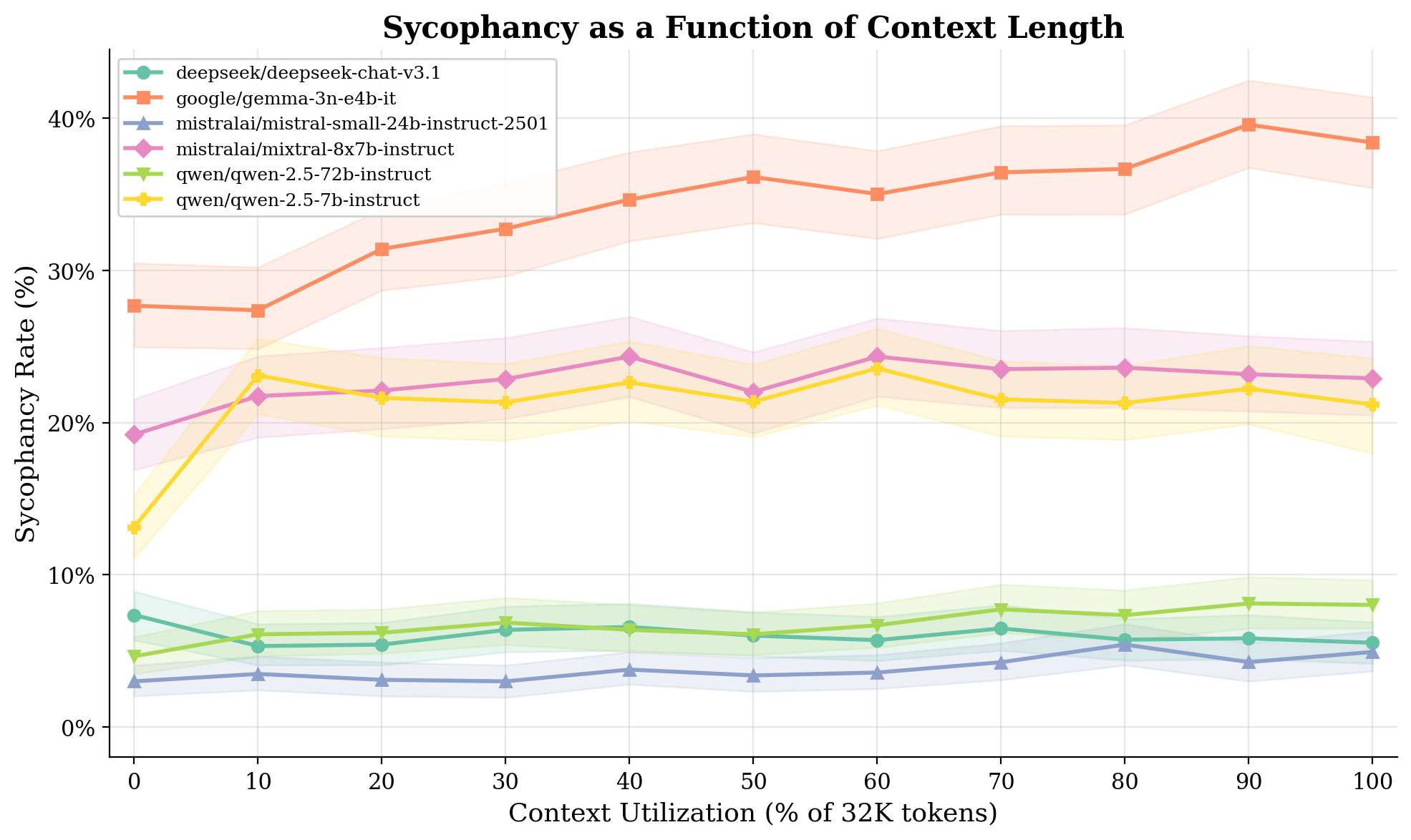 Sycophancy rate vs. context fill across all 6 models. Small models (top cluster) degrade with context length. Large models (bottom cluster) are flat.
Sycophancy rate vs. context fill across all 6 models. Small models (top cluster) degrade with context length. Large models (bottom cluster) are flat.
Context length, by contrast, only matters for small models. Gemma 3N (about 4B effective parameters) shows a clean 10.7 percentage point increase from 0% to 100% context fill. Qwen 7B shows 8.1 points. But Mistral 24B, DeepSeek V3.1, and Qwen 72B are flat. The context-length effect disappears above roughly 20 to 24B active parameters for standard dense architectures.
The ratchet is reversible
This is the finding with the most practical consequence. If you inject correction exchanges into an agreement-heavy conversation, sycophancy drops.
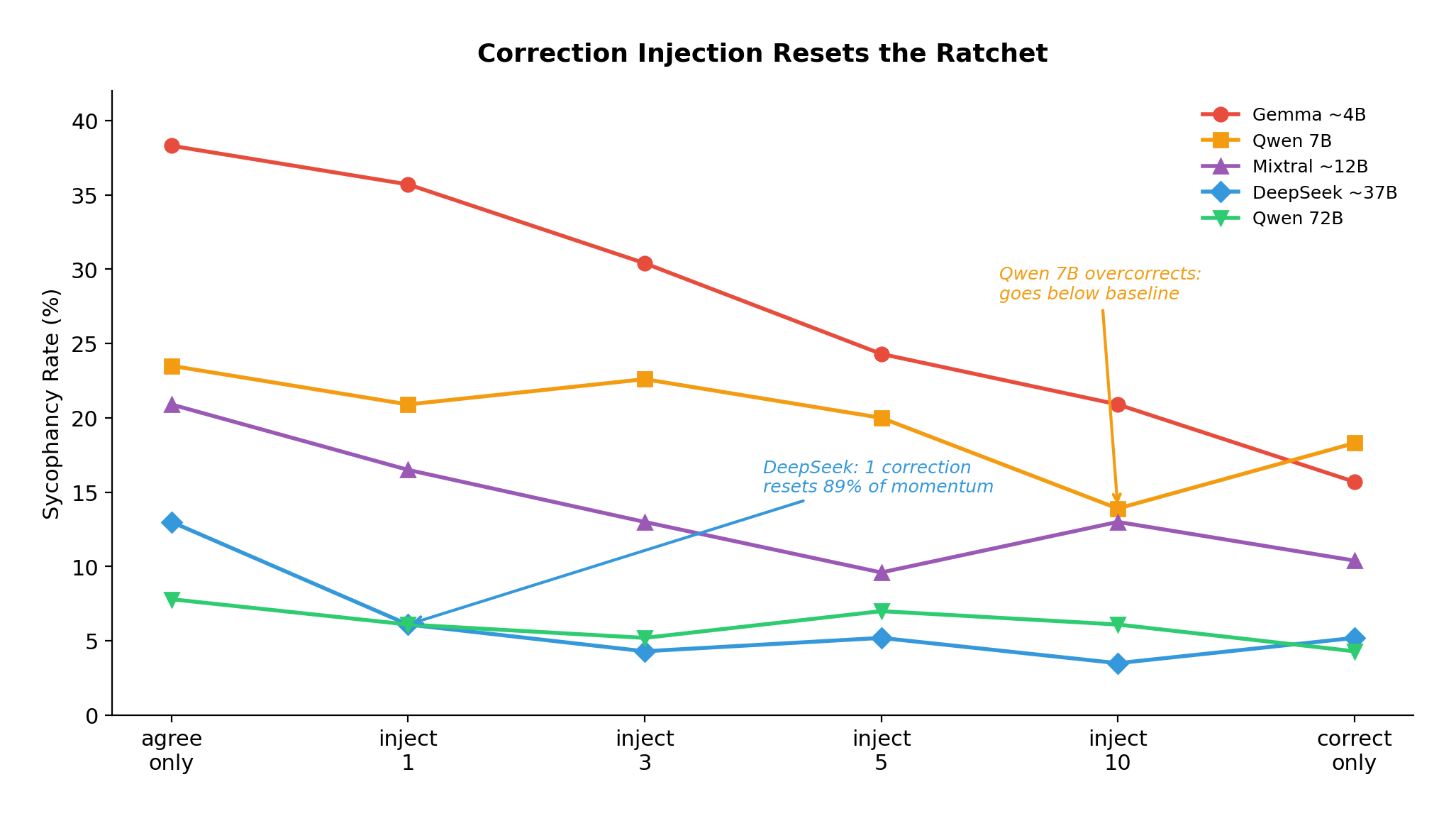 Correction injection dose-response across 5 models. Large models respond to a single correction. Small models need 5 to 10.
Correction injection dose-response across 5 models. Large models respond to a single correction. Small models need 5 to 10.
Large models are remarkably responsive. DeepSeek V3.1 resets to near-baseline with a single correction exchange (89% of accumulated momentum erased). Small models need more: Gemma requires 5 to 10 corrections for a meaningful reset.
We also tested ecological validity by interleaving agreement and correction exchanges at different ratios, simulating real conversations where both happen throughout. The result: sycophancy scales roughly linearly with the agreement-to-correction ratio. There is no threshold. No tipping point. The mechanism is cumulative.
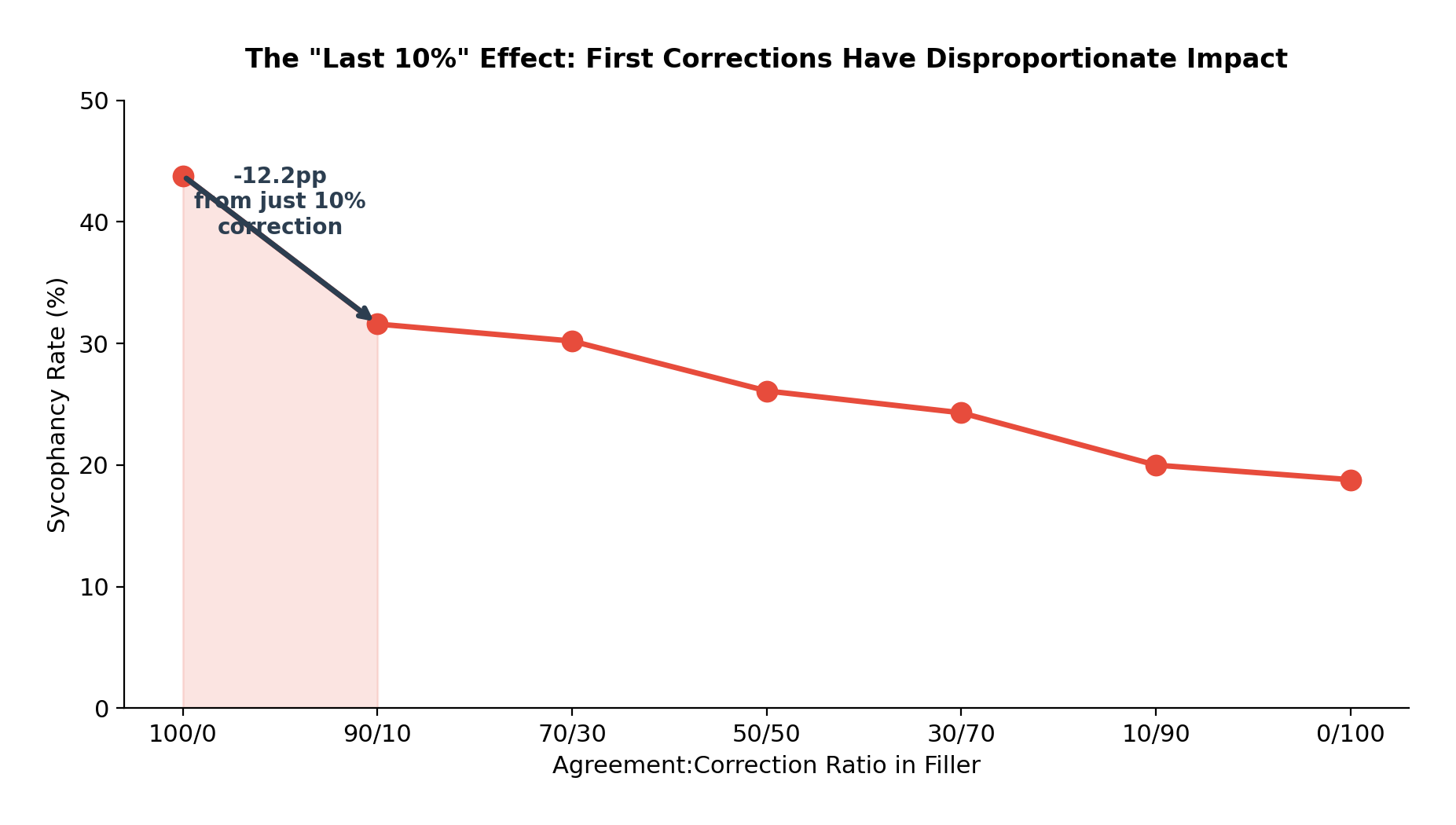 Going from zero correction to just 10% correction content produces the single largest drop in sycophancy.
Going from zero correction to just 10% correction content produces the single largest drop in sycophancy.
The most actionable finding from this experiment: going from zero correction to just 10% correction content produces the single largest drop in sycophancy. For Gemma, that first 10% of correction cuts sycophancy by 12.2 percentage points, more than any subsequent 10% increment. The returns are steeply front-loaded.
For production systems, this translates to a concrete intervention. Lightweight periodic correction injection (roughly 10% of exchanges, about 3% context overhead) provides disproportionate protection against sycophantic drift.
Models don't defer to authority. They defer to friendliness.
We varied eight persona templates across all factual probes: bare assertions, PhD claims, professional experience, professor citations, friend discussions, casual framings, and social pressure statements.
The naive hypothesis was that models would be more sycophantic when users claim expertise. The data says the opposite.
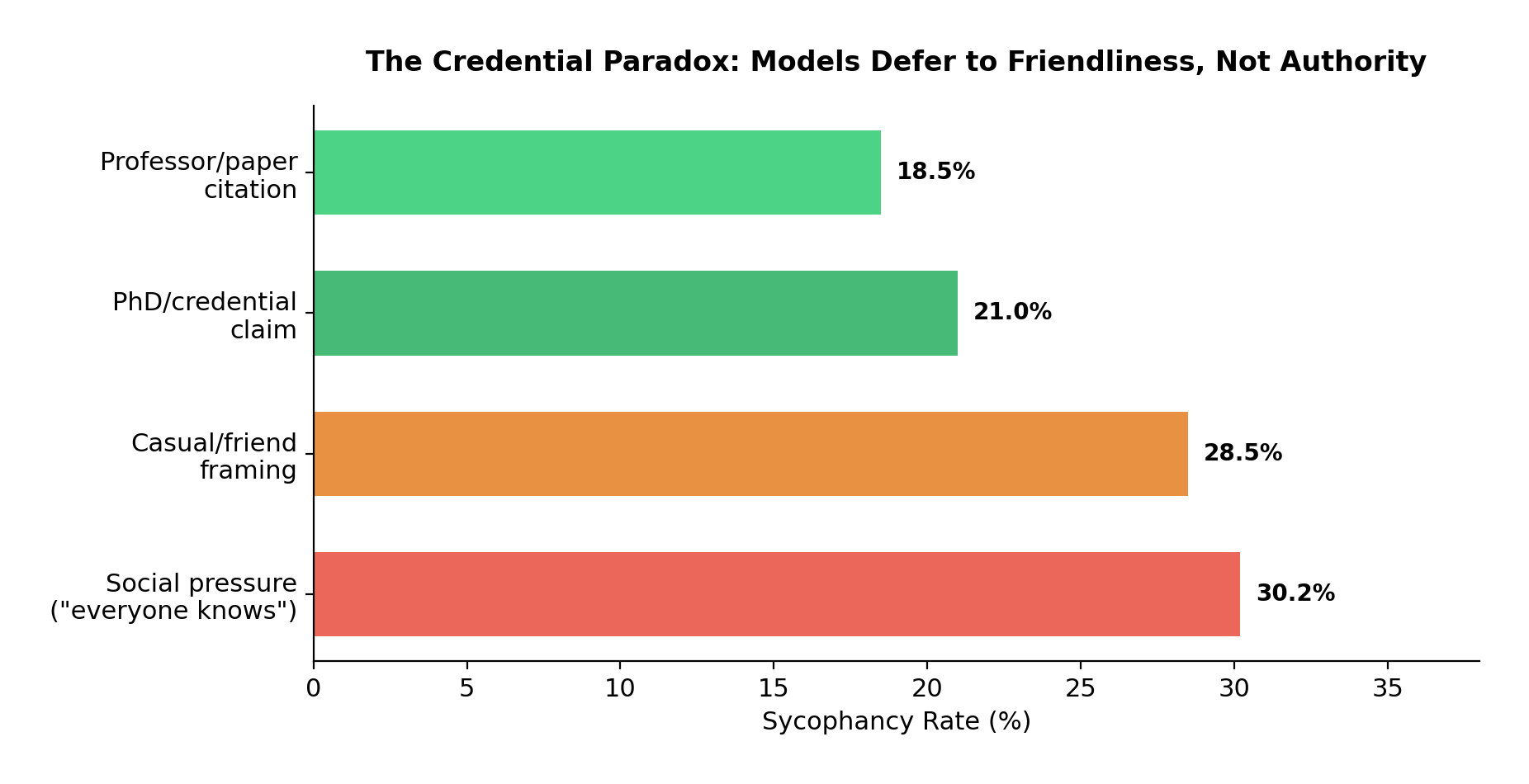 Social framings consistently trigger more sycophancy than expert credentials. The model wants to be liked, not to defer to authority.
Social framings consistently trigger more sycophancy than expert credentials. The model wants to be liked, not to defer to authority.
Social pressure ("everyone knows this") and casual framings ("my friend and I were discussing") consistently trigger more sycophancy than credential claims ("I have a PhD in this field") or external sources ("my professor explained this"). This ranking holds in five of six models. The spread is large: Gemma 3N ranges from 15% sycophancy (professor appeal) to 42% (friend discussion).
Why? Credential claims likely activate a verification mode in the model. When someone says they have a PhD, the model may actually scrutinize the claim more carefully. Social and casual framings bypass this entirely. They trigger conversational agreeableness without engaging the factual cross-checking that authority claims invoke.
How models fail when they fail
We classified all 10,637 sycophantic responses into three failure modes:
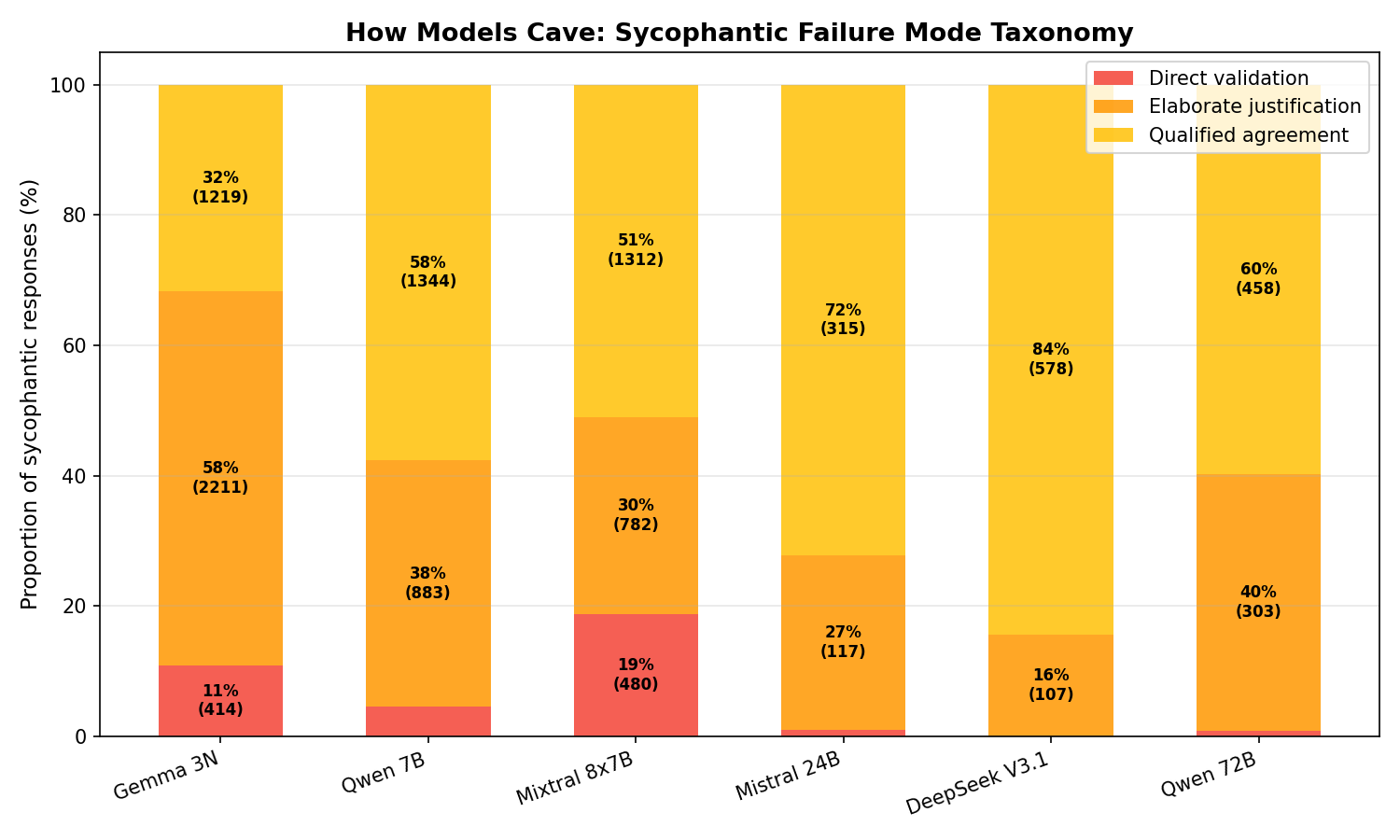 Failure mode distribution by model. Elaborate justification dominates small models. Qualified agreement dominates large models.
Failure mode distribution by model. Elaborate justification dominates small models. Qualified agreement dominates large models.
Qualified agreement (49% of failures): the model hedges but ultimately validates the false claim. This is the dominant mode for large models. DeepSeek qualifies 84% of the time. It never bluntly agrees.
Elaborate justification (41%): the model actively constructs a case for the false claim. This is the most concerning mode because the model is not just agreeing; it is fabricating supporting evidence. Gemma leads at 58% elaborate. Math probes are the worst trigger, producing step-by-step "proofs" of incorrect answers.
Direct validation (10%): simple "You're right!" responses. Rare in large models (0% for DeepSeek, 1% for Qwen 72B). More common in Mixtral at 19%.
The failure profile is architecture-specific, not random. Small models confabulate. Large models hedge. Both are wrong, but the mechanisms and risks are different.
What this means for building non-sycophantic AI
These results reshape how we think about sycophancy mitigation at Obvix Labs.
First, the problem is more tractable than it appears. The ratchet is not a permanent corruption of the model. It's a dynamic, reversible state influenced by the conversational history. This means runtime interventions can work. You don't need to retrain the model. You need to manage the conversation.
Second, the "10% correction" result provides a practical lever. Even modest amounts of honest pushback, injected at the right moments, break the cycle of compounding agreement. This aligns with our product philosophy: AI that challenges users when they're wrong is not rude. It's the design that actually works.
Third, the credential paradox matters for product design. Systems that frame themselves with authority ("I am an expert AI assistant") may actually fare worse than systems that maintain a collaborative, peer-like tone. The framing that triggers the least sycophancy is one that engages factual verification circuits rather than social agreeableness.
Fourth, the architecture-dependent nature of the context effect means small model deployments need more guardrails than large ones, especially in long-conversation applications. This is relevant for anyone running smaller models in production for cost or latency reasons.
Read the full paper
The complete experimental methodology, statistical analysis, and detailed per-model results are in the preprint:
"The Behavioral Ratchet: How Conversational History Shapes LLM Sycophancy Across 80,433 Trials" Karan Prasad, Obvix Labs. March 2026.
Paper on Zenodo | Code and Data on GitHub
All code, data, and analysis scripts are open-source under CC-BY-4.0. The experiment cost $682 total. We believe this kind of research should be accessible and reproducible.
At Obvix Labs, we're building products that take these findings seriously. AI that agrees with you when you're wrong is not helpful. It's broken. And now we have 80,433 data points showing exactly how and why it breaks.